Menú Principal
No más sorteos por letra
Este tipo de sorteos se utilizan insistentemente
por todas las administraciones. Consisten, habitualmente, en escoger al azar
dos letras iniciales del primer apellido y adjudicar, a partir de ahí, los
apellidos seleccionados siguiendo el orden alfabético. Se utilizan para oposiciones,
comisiones, tribunales, mesas electorales, matrículas en colegios, etc. Y si
me apuras, incluso en el Congreso y el Senado. Me suena algo relativo a “…
cualquier otra condición o circunstancia personal o social”. Pues bien, resulta
que estos sorteos son enormemente injustos porque los candidatos no tienen la
misma probabilidad de ser seleccionados. En ocasiones, incluso puede suceder que
todos los candidatos tengan probabilidades distintas de ser seleccionados. En términos generales, en
una primera aproximación, puede afirmarse que tienen menos opciones los
apellidos situados detrás de los más habituales. Es decir, que tienen un escudo
que “les protege” e impide que les llegue “la suerte”.
Tal vez no deberíamos preocuparnos
por estos sorteos que suenan a sopas de letras. Parece que están siempre en
otra parte y son insignificantes desde la lejanía de los otros. Pero al final,
las barbas del vecino acaban llamando también a tu puerta.
Casi todos los años se publica en
Internet algún excelente artículo al respecto:
¿Por
qué el sorteo por letra es el más injusto? (Joseángel Murcia 1/02/2016).
El
sorteo por apellidos: la gran injusticia de la administración (Clara Grima 31/05/2017).
Desmontando
(una vez más) los absurdos sorteos por letra (Miguel A. Morales 28/02/2018).
Pero da igual, aunque se diga mil
veces, no hay manera. En las oficinas de las diferentes administraciones
piensan que es un cuento de los matemáticos y no se lo creen… Tienen que verlo
con sus ojos. Aquí sólo puedo decir que Henri Poincaré afirmó que el azar no es
más que la medida de nuestra ignorancia.
Para estas cuestiones, los matemáticos juegan con ventaja, pero no por dominar más
o menos matemáticas o probabilidades, sino por estar acostumbrados a demostrar
que algo es falso sin más que dar un contraejemplo. No se necesitan mil ejemplos,
basta con uno. En este caso, sería un
ejemplo en el que quede bien claro que la situación no es equitativa. Y
ese va a ser mi granito de arena. Repetiré una vez más ejemplos que muestren
que es un sorteo injusto y, además, proporcionaré gaseosa para hacer los
experimentos antes del sorteo con el siguiente enlace:
 Si alguien piensa hacer un
sorteo por letra y, previamente al sorteo, prueba y copia los nombres
de los participantes, observará las probabilidades de cada uno antes del
sorteo. Entonces, con toda seguridad, desistirá y buscará otra forma diferente de realizar el
sorteo…
Si alguien piensa hacer un
sorteo por letra y, previamente al sorteo, prueba y copia los nombres
de los participantes, observará las probabilidades de cada uno antes del
sorteo. Entonces, con toda seguridad, desistirá y buscará otra forma diferente de realizar el
sorteo…Hagamos un poco de historia. En el
sorteo de los excedentes de cupo del reemplazo de 1998, es decir, los jóvenes
que por sorteo se libraban de hacer el servicio militar obligatorio, había un total de
165.342 jóvenes y resultaron excedentes de cupo 16.442. Para realizar el
sorteo, se utilizaron 6 bombos. En el bombo de las centenas de millar había cinco
bolas con el número 0 y otras cinco con el número 1. Se sacó una bola de cada bombo
y a partir de ahí se contaron excedentes de cupo. Claramente, el sorteo fue
injusto porque los reclutas cuyo número figuraba entre el 16.442 y el 99.999 tenían menos posibilidades que los demás porque los números con seis cifras
significativas (“ciento y pico mil…”), tenían mayor probabilidad de salir en
los bombos, por tener un peso específico del 50%, siendo bastantes menos del 50%.
Lo más práctico hubiera sido elegir
de manera informática un número aleatorio o coeficiente entre 0 y 1,
multiplicarlo por el total de 165.342, sumarle 1 y tomar la parte entera
olvidando los decimales. En Excel sería así: =ENTERO(ALEATORIO()*165342+1).
Puede decirse que eso es un sorteo
con números y no guarda relación, pero resulta que en los sorteos por letra se
comete el mismo error, pero todavía con mayor arbitrariedad, y la injusticia
es más exagerada, si cabe, porque las diferencias entre las probabilidades
de cada candidato pueden ser enormes. Veamos un primer ejemplo con letras: un sorteo de un
coche entre mil personas extrayendo como siempre dos letras iniciales del
primer apellido. Resulta que, siguiendo la estadística de los apellidos
españoles, unos 900 participantes no pueden resultar premiados ya que sus dos
letras iniciales están detrás de alguien con esas mismas letras iniciales (por
ejemplo el 2º Fernández y siguientes, el 2º Rodríguez y siguientes, etc.). Estos participantes tienen probabilidad 0% de ganar el coche, ¡que mala suerte!...
Y quedan sólo unos 100 con sus dos iniciales únicas o coincidentes con otros,
pero situados en el primer puesto, o sea, el primer García, el primer Martínez,
etc. El coche se lo llevará al final uno de esos 100 que ven de forma gratuita
como se han multiplicado sus aspiraciones de ganar.
Podría decirse que el anterior es
con letras, pero que es un ejemplo extremo. Bueno, pues veamos uno más
sencillo, con nombres concretos de una asociación y se eligen los tres cargos directivos en un sorteo por letra. En este ejemplo resulta que todos los participantes
tienen sus probabilidades diferentes, o sea, que como sorteo sería de todo,
menos equitativo.

Pero si todavía se insiste en que son ejemplos rebuscados y
que en la práctica las cosas son diferentes y suceden de una forma más natural,
pues vamos a ver un último ejemplo lo más real posible. Tomamos una muestra de
1000 nombres y apellidos siguiendo las proporciones estadísticas de apellidos
españoles (García, González, Rodríguez, Fernández, López, Martínez, Sánchez,
Pérez, Gómez, Martín, etc.) y vamos a seleccionar 150 personas. Puedes ver los
resultados en este enlace:
Lo primero que observamos es que no hay prácticamente ninguna
relación entre los porcentajes iniciales de repetición de las letras y su
probabilidad media de ser seleccionadas, como puede observarse en los dos
gráficos siguientes: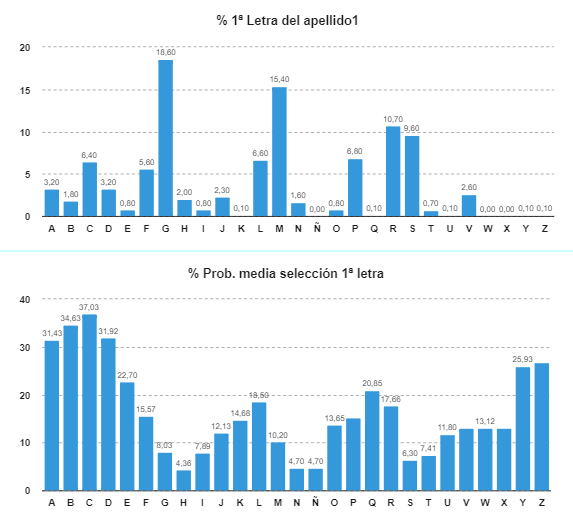
En segundo lugar, vemos que la injusticia es mayúscula, con
diferencias de hasta siete veces más unas letras que otras. Las letras con
mayores probabilidades (C, B, D y A) son las más probables porque están desprotegidas,
ya que en las letras anteriores hay pocos apellidos. Es decir, como hay pocas
personas con apellidos en las últimas letras del abecedario, las ruedas que
comienzan en estas últimas letras llegan casi seguro hasta las primeras letras.
Por el contrario, las letras con escasas probabilidades (H, N, Ñ -muy inusual- y S) están muy
protegidas porque en las letras inmediatamente anteriores están los apellidos
más numerosos.
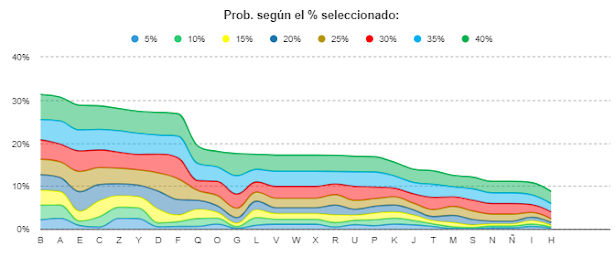
En tercer lugar, siguiendo con el mismo ejemplo y variando
el porcentaje de personas seleccionadas, llegamos a conclusiones más generales:
las letras con mayor probabilidad son B, A, E y C, y las letras menos
probables son H, I, Ñ -muy inusual-, N y S.
¿Y entonces, cómo
tendría que hacerse el sorteo?
Utilizando números. Se
ordenan los participantes por cualquier procedimiento: alfabéticamente, por fecha de
nacimiento, por antigüedad, por expediente, por NIF, etc., y se les asigna a cada uno un número. Supongamos que hay 72 personas
y queremos seleccionar 5. Elegimos ahora de manera informática un número
aleatorio o coeficiente entre 0 y 1, lo multiplicamos por el total de 72, le
sumamos 1 y tomamos la parte entera, olvidando los decimales. En Excel, sería la
función: =ENTERO(ALEATORIO()*72+1). Ha
salido el 48, y se seleccionan entonces del 48 al 52.
También se puede hacer
a mano:
- Ordenamos los participantes de cualquier forma, por ejemplo, en orden alfabético y les asignamos a cada uno un número. Supongamos que hay 72.
- Ponemos en una bolsa escritos en papelitos (bolas, garbanzos, etc.) los dígitos del 0 al 9, como en un bombo de la ONCE.
- Realizamos 5 extracciones con reemplazamiento y resultará un número de 5 cifras como en el sorteo de la ONCE. Imaginemos que sale el 65.438.
- Multiplicamos por 72 y dividimos por 100.000, que sería como cambiar de escala o aplicar una regla de 3 (tendremos entonces un número decimal que irá desde 0 hasta 71 “y pico”). Resultaría en el ejemplo: 47,11536.
- Sumamos 1 (pasaríamos a un número decimal desde 1 hasta 72 “y pico”). Siguiendo con el ejemplo, tendríamos el 48,11536.
- Tomamos la parte entera y despreciamos los decimales (pasando a un nº natural que va de 1 a 72). Ha salido el 48 y se seleccionan desde el 48 al 52.
¿Y si al final sale la
misma letra que si hubiéramos hecho el sorteo por letra?
Pues podría suceder
que al final saliese también en el sorteo por letra la persona que ocupa el
lugar 48. Pero eso es lo mismo que sucede cuando le toca la lotería a alguien
con un único décimo y el que lleva muchos décimos no le toca nada. Lo importante son las probabilidades antes del sorteo y que todos estemos en
igualdad de condiciones. Después del sorteo, los décimos o boletos van directos a
la basura.
Toda la vida con estos sorteos para nada... ¿No podría
arreglarse de alguna forma?
No, no se puede. Al intentar arreglarlo y sortear repetidamente hasta encontrar las iniciales de
alguien, el 2º García no sería elegido en la primera ocasión y el 8º García no
podría salir si hay 7 seleccionados. El menos malo de estos sorteos consistiría en utilizar
la
letra del NIF. Seguiría siendo también un sorteo injusto,
ya que habría más de unas letras que de otras, pero la distribución de
estas letras es más uniforme que las letras iniciales de los apellidos. Para encontrar un sorteo justo habría que
crearlo artificialmente, por ejemplo con 729 apellidos y cada uno con las dos
iniciales diferentes, sería un ejemplo tan remoto como las parejas del arca de
Noé, con 729 (27x27) parejas de letras iniciales, desde AA hasta ZZ, por ejemplo XX y XY se corresponderían con los números 673 y 674.
No, no amig@, no, no hay ninguna manera, no hay por donde
cogerlo, un sorteo por letra es una barbaridad.
Cuando compremos este año un décimo para el sorteo del gordo
de Navidad, seguro que el señor lotero nos dice: “Buenos días, a usted por
apellidarse Bobadilla, le corresponden 5 décimos por el mismo precio, ¿qué le
parece? y responderemos: ¡Ah, sí, sí, claro, claro, estupendo! Porque
evidentemente pensaremos que está de guasa...